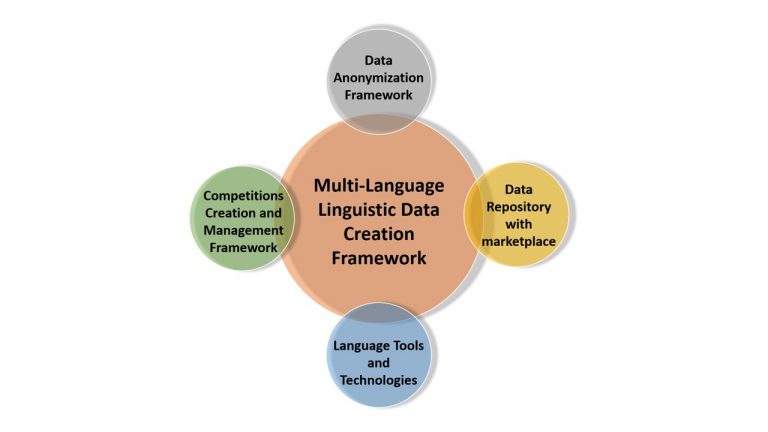
ज्ञान संपदा ही एक बहु-भाषिक “भाषाशास्त्र डेटा निर्मिती फ्रेमवर्क (ML-LDCF)” आहे ज्यामध्ये, स्पर्धा – “निर्माण आणि व्यवस्थापन फ्रेमवर्क (CCMF)” आणि “डेटा अनामिकरण फ्रेमवर्क (DAF)” यांचा क्राउडसोर्स मॉडेल सहित सहभाग आहे
भाषिक डेटा, विविध नॅचरल लैंग्वेज प्रोसेसिंग टूल्स आणि कृत्रिम बुद्धिमत्ता तंत्रांच्या मदतीने तयार केला जातो आणि मशीन लर्निंग आणि किंवा कृत्रिम बुद्धिमत्ता संशोधनासाठी डेटा वापरण्यापूर्वी डेटा अनामिकरण फ्रेमवर्क (DAF) चा वापर केला जातो.
ज्ञानसंपदा तीन स्वरूपामध्ये उपलब्ध आहे. उदा. क्लाउड सेवा, क्लायंट-साइड होस्टिंग आणि विविध अनुप्रयोगांमध्ये एप्लीकेशन प्रोग्रामिंग इंटरफेस (API) च्या स्वरूपात.