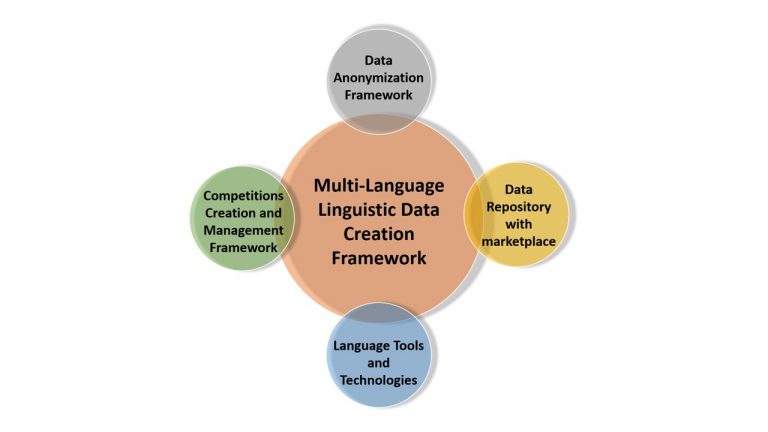
ज्ञानसंपदा एक बहु-भाषा, “भाषाई डेटा निर्माण ढांचा (एमएल-एलडीसीएफ)” है जिसमें “प्रतियोगिता-निर्माण और प्रबंधन फ्रेमवर्क (सीसीएमएफ)” और “डेटा अनामीकरण फ्रेमवर्क (डीएएफ)”, क्राउड सोर्स मॉडल के साथ मिलकर बनता है।
भाषाई डेटा विभिन्न प्राकृतिक भाषा प्रसंस्करण उपकरणों और कृत्रिम बुद्धिमत्ता तकनीकों की मदद से उत्पन्न होता है, और मशीन लर्निंग और या कृत्रिम बुद्धिमत्ता अनुसंधान के लिए डेटा का उपयोग करने से पहले एक डेटा अनामीकरण फ्रेमवर्क (DAF) का उपयोग किया जाता है।
ज्ञानसंपदा तीन रूपों में उपलब्ध है। उदा. क्लाउड सेवाएं, क्लाइंट-साइड होस्टिंग और विभिन्न अनुप्रयोगों में एप्लिकेशन प्रोग्रामिंग इंटरफेस (एपीआई) के रूप में